
Why HTML5 alone can't unify videos and the web
Julien, 26 juillet 2011
For documents, the web is the API
If you were to draw a map of videos on the web, you would find that your map is composed mostly of dead-ends.
HTML 5 started a big change for video, making in it a «first class citizen of the web». We can manipulate videos via Javascript and CSS. Media files are exposed as web resources, referenced natively via URLs.
But there is other dead-ends for web videos. Data dead-ends. Findability dead-ends.
When you hit a video on the web – or an audio media, for that matter – its subtitles are segregated in file silos, meta-data is not exposed.
Even licenses are rarely linked from the video – mostly when they are from the Creative Commons family, a funny paradox in a copyright obsessed world.
For example, this kind of geo-block :
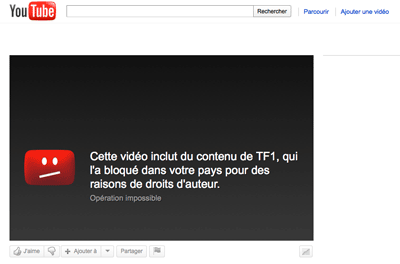
on a video is not exposed in the HTML in any data format at all. It should.
Even the useful interactive transcripts, adopted by innovative video platforms like TED and YouTube, turn into dead-ends, using incompatible tools and formats.
They mostly use Flash players, at the moment, but it’s not really the point: there is working interactive transcript in pure HTML 5 and Javascript, thanks to the Popcorn.js library and clever hackers like Henrik and Mark:
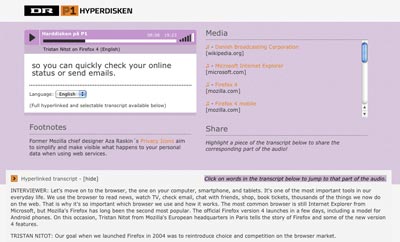
Even using HTML 5, the transcripts are still mostly stored like subtitles files, as external, non hypertext, static files. They only become useful thanks to the code that use them.
They represent another dead-end on the web, a data document out of band, non-browser friendly and that links nowhere without the proper code.
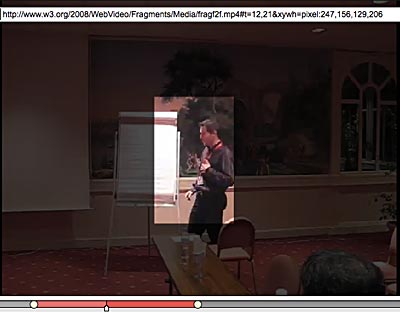
For documents, the web is the API. We need to bring media meta-data back in the HTML document. And that meta-data, transcripts, license, location, people, emotions or objects must link to the resource concerned, using URIs, in particular Media Fragments:
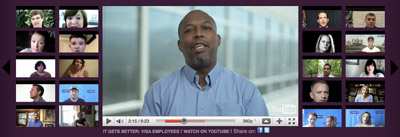
With exemplar use cases like itgetsbetter.org it’s easier to evaluate existing tools and standards. We want to turn a video-rich but data-poor project into a data-rich resource for journalists, activists, artists and scientists.
With that design goal in mind, we ask ourselves, «should we use this technology?». Do we feel enthusiasm, do we find the technology simple, open and rich enough to help us reach our goal? If not, it’s probably not the right technology.
This week I started to talk with the Web Made Movies / Popcorn.js community. It’s a small but dedicated open source community building a great javascript video and audio manipulation library, and I wanted to know what they were using today, and what they could use tomorrow to store and use media meta-data in their projects.
In the spirit of working in the open, here are the result of a week of reviewing the state of web video (meta) data. It’s NOT a blog post, but a work document that sketches a quick panorama of where we are in term of turning web videos into citizens of the ‘web of data’ (hint: not very far)
I know have a much better understanding of the technical needs to reach my goal:
- a simple, common-sense standard that store video and audio timed meta-data alongside the media itself in HTML,
- a proof-of-concept tool to create and edit this timed data,
- and a separate Popcorn.js plugin would be the end user player first brick
For this to work, I’ll work closely with the Web Made Movies community, where already 3 persons have manifested their interest – Mark Boas, Samuel Huron and Nick Doiron, all of them also Learning Lab fellows!